KI Champions League Vorhersage xG: Expected Goals als Prognose-Fundament
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Es gibt Kennzahlen, die den Fußball verändert haben, und dann gibt es Expected Goals. Was vor einem Jahrzehnt noch ein Nischenthema für Statistik-Enthusiasten war, ist heute aus der professionellen Spielanalyse nicht mehr wegzudenken. Die Abkürzung xG taucht in Fernsehübertragungen auf, Trainer sprechen davon in Pressekonferenzen, und wer moderne KI-Vorhersagen für die Champions League verstehen will, kommt an diesem Konzept nicht vorbei. Expected Goals ist nicht irgendeine Metrik unter vielen, sondern das Herzstück dessen, wie Algorithmen Fußballspiele bewerten und Prognosen erstellen.
Die Grundidee klingt simpel: Jeder Torschuss bekommt einen Wert zwischen null und eins, der angibt, wie wahrscheinlich es ist, dass dieser Schuss in einem Tor resultiert. Ein Elfmeter hat einen hohen xG-Wert, ein Fernschuss aus dreißig Metern einen niedrigen. Doch hinter dieser scheinbaren Einfachheit verbirgt sich eine mathematische Tiefe, die den Unterschied zwischen oberflächlicher Statistik und echter Analyse ausmacht. Um zu verstehen, warum xG für KI-Vorhersagen so zentral ist, muss man tiefer in die Materie eintauchen.
Dieser Leitfaden nimmt Expected Goals unter die Lupe: wie die Kennzahl berechnet wird, welche Faktoren einfließen, wie KI-Systeme xG-Daten verarbeiten und welche Grenzen das Modell hat. Für alle, die ihre Champions-League-Analysen auf ein solideres Fundament stellen wollen, ist dieses Wissen unverzichtbar. Und für alle anderen: Es ist schlicht faszinierend zu verstehen, wie Mathematik und Fußball zusammenfinden.
Die Entstehung einer revolutionären Metrik
Bevor wir uns der technischen Seite widmen, lohnt ein Blick auf die Geschichte. Expected Goals ist keine Erfindung der jüngsten Jahre, auch wenn es erst in den letzten zehn Jahren zum Mainstream-Begriff geworden ist. Die konzeptionellen Grundlagen reichen weiter zurück, und verschiedene Analysten haben parallel an ähnlichen Ideen gearbeitet.
Die Kernfrage, die xG beantwortet, ist so alt wie der Fußball selbst: War ein Tor glücklich oder verdient? Hat eine Mannschaft gewonnen, weil sie besser gespielt hat, oder weil sie Glück hatte? Die traditionelle Antwort auf diese Frage war subjektiv, basierend auf dem Eindruck des Betrachters. Expected Goals objektiviert diese Frage, indem es jeden Torschuss anhand historischer Daten bewertet.
Die praktische Umsetzung wurde durch zwei Entwicklungen ermöglicht. Erstens die Verfügbarkeit detaillierter Schussdaten: Position auf dem Spielfeld, Spielsituation, Art des Abschlusses und mehr werden heute für jeden Profifußballspiel erfasst. Zweitens die Rechenkapazität, um Hunderttausende von historischen Schüssen zu analysieren und daraus Modelle abzuleiten. Anbieter wie Opta, StatsBomb und andere haben diese Dateninfrastruktur geschaffen, auf der moderne xG-Modelle aufbauen.
Heute ist xG so etabliert, dass die Bundesliga seit der Saison 2020/21 in Zusammenarbeit mit AWS unter dem Label Match Facts eigene xG-Werte in Echtzeit berechnet und in den Übertragungen anzeigt. Die UEFA veröffentlicht xG-Statistiken für Champions-League-Spiele. Wettanbieter nutzen xG-basierte Modelle für ihre Quotenfestlegung. Die Metrik ist vom akademischen Konzept zum Industriestandard geworden.
Die mathematische Grundlage verstehen
Die Berechnung eines xG-Werts beginnt mit einer scheinbar einfachen Frage: Wie oft wurde aus einer vergleichbaren Position in der Vergangenheit getroffen? Doch die Definition von vergleichbar ist der komplizierte Teil. Moderne xG-Modelle berücksichtigen eine Vielzahl von Faktoren, die die Torwahrscheinlichkeit beeinflussen.

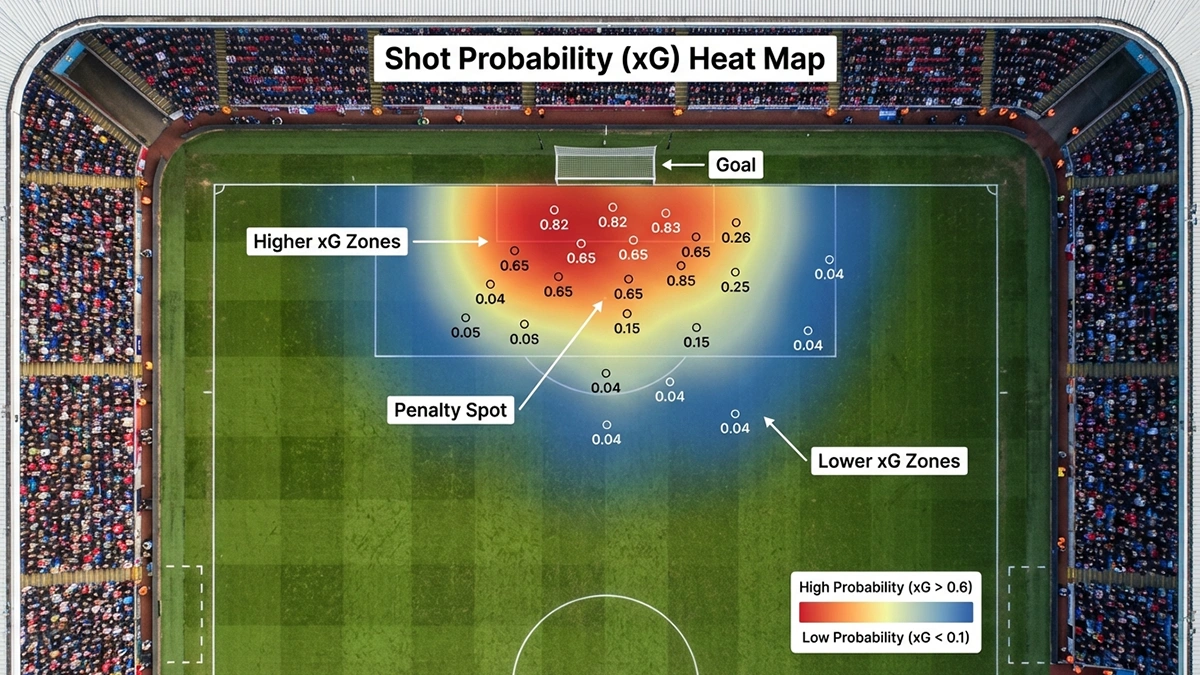
Die Entfernung zum Tor ist der offensichtlichste Faktor. Ein Schuss aus fünf Metern hat eine höhere Trefferwahrscheinlichkeit als einer aus zwanzig Metern. Die Beziehung ist nicht linear: Die Wahrscheinlichkeit sinkt nicht gleichmäßig mit zunehmender Distanz, sondern folgt einer komplexeren Kurve. In der Nähe des Tores ist der Gradient steiler, in größerer Entfernung flacht er ab.
Der Winkel zum Tor ist ebenfalls entscheidend. Ein Schuss aus zentraler Position bietet dem Schützen mehr vom Tor als Zielfläche als ein Schuss aus spitzem Winkel. Die Geometrie spielt hier eine wichtige Rolle: Je weiter der Spieler zur Seite steht, desto mehr Tor wird vom Pfosten und dem Torwart verdeckt. Die besten xG-Modelle berechnen den exakten Sichtbereich auf das Tor und nutzen ihn als Variable.
Die Art des Abschlusses fließt ebenfalls ein. Ein Schuss mit dem Fuß hat eine andere Trefferwahrscheinlichkeit als ein Kopfball. Innerhalb der Kopfbälle macht es einen Unterschied, ob der Spieler hochspringen musste, ob er den Ball aus dem Lauf oder im Stand erreicht hat. Auch die Frage, ob der starke oder der schwache Fuß genutzt wurde, kann berücksichtigt werden, wobei diese Information nicht immer verfügbar ist.
Die Spielsituation vor dem Schuss ist ein weiterer wichtiger Faktor. Ein Schuss nach einem Konter, bei dem die Abwehr noch nicht geordnet ist, hat eine höhere Trefferwahrscheinlichkeit als derselbe Schuss nach einem längeren Angriff, bei dem die Verteidigung Zeit hatte, sich zu formieren. Ebenso unterscheiden sich Schüsse nach Flanken von solchen nach Dribbling oder Durchbrüchen. Der Pass, der zum Schuss führt, kann die Torwahrscheinlichkeit erhöhen oder senken, je nachdem wie gut er den Schützen in Position bringt.
Fortgeschrittene Modelle berücksichtigen zusätzlich die Position der Verteidiger und des Torwarts zum Zeitpunkt des Schusses. Ein offenes Tor erhöht den xG-Wert dramatisch, während ein gut positionierter Torwart ihn senkt. Diese Informationen sind nicht immer verfügbar, da sie präzise Tracking-Daten erfordern, aber wo sie vorhanden sind, verbessern sie die Genauigkeit der Modelle erheblich.
Pre-Shot xG und Post-Shot xG
Eine wichtige Unterscheidung, die oft übersehen wird, ist die zwischen Pre-Shot xG und Post-Shot xG. Diese Begriffe beschreiben verschiedene Stufen der Analyse und haben unterschiedliche Anwendungsbereiche.
Pre-Shot xG, manchmal auch als klassisches xG bezeichnet, berücksichtigt alle Faktoren bis zum Moment des Schusses: Position, Winkel, Spielsituation, aber nicht die Qualität des Schusses selbst. Es beantwortet die Frage, wie wahrscheinlich ein Tor aus dieser Situation ist, unabhängig davon, wie gut der Schuss ausgeführt wurde. Diese Metrik ist besonders nützlich, um die Qualität der Chancen zu bewerten, die eine Mannschaft herausspielt.
Post-Shot xG, auch als xGOT bekannt, erweitert die Analyse um die Platzierung des Schusses. Ein Schuss, der zentral auf den Torwart geht, hat eine niedrigere Post-Shot-Wahrscheinlichkeit als einer, der in die Ecke fliegt. Diese Metrik berücksichtigt also nicht nur die Situation vor dem Schuss, sondern auch die Ausführungsqualität. Sie ist besonders nützlich, um die Abschlussqualität einzelner Spieler zu bewerten.

Für KI-Vorhersagen sind beide Metriken relevant, aber auf unterschiedliche Weise. Pre-Shot xG ist besser geeignet, um die Offensivqualität einer Mannschaft zu bewerten, weil es die strukturellen Stärken misst: die Fähigkeit, hochwertige Chancen zu kreieren. Post-Shot xG ist nützlicher, um zu verstehen, warum eine Mannschaft unter- oder überperformt hat, also mehr oder weniger Tore erzielt hat, als ihr Pre-Shot xG erwarten ließ.
Die Differenz zwischen beiden Werten gibt Aufschluss über die Abschlussqualität. Ein Spieler, dessen Post-Shot xG konstant höher ist als sein Pre-Shot xG, verfügt über überdurchschnittliche Abschlusstechnik. Umgekehrt deutet ein konstant niedrigerer Post-Shot-Wert auf Schwächen im Abschluss hin. Diese Information ist wertvoll für die Prognose, weil sie hilft, systematische Über- oder Unterperformance zu identifizieren.
Wie KI-Systeme xG-Daten verarbeiten
Für Machine-Learning-Modelle, die Fußballergebnisse vorhersagen, ist xG ein zentraler Input. Die Integration erfolgt auf verschiedenen Ebenen, und die Art der Nutzung unterscheidet einfache von fortgeschrittenen Systemen.
Auf der grundlegendsten Ebene nutzen KI-Modelle aggregierte xG-Werte als Feature. Der durchschnittliche xG-Wert einer Mannschaft über die letzten fünf oder zehn Spiele gibt Aufschluss über ihre Offensivstärke. Ebenso zeigt der xG-against-Wert, also die erwarteten Gegentore, die Qualität der Defensive. Die Differenz zwischen beiden, manchmal als xGD bezeichnet, ist ein Maß für die Gesamtspielstärke.
Fortgeschrittenere Modelle gehen tiefer und analysieren die Verteilung der xG-Werte, nicht nur den Durchschnitt. Eine Mannschaft, die regelmäßig Chancen mit hohem xG kreiert, ist anders zu bewerten als eine, die viele Schüsse mit niedrigem xG abgibt. Die Varianz der xG-Werte kann ebenfalls informativ sein: Ein Team mit stabilen Werten ist vorhersehbarer als eines mit großen Schwankungen.
Die zeitliche Dimension spielt ebenfalls eine Rolle. KI-Systeme gewichten aktuellere xG-Daten typischerweise stärker als ältere. Ein Team, das vor fünf Spielen noch gute xG-Werte hatte, aber in den letzten drei Spielen eingebrochen ist, sollte anders bewertet werden als eines mit konstanter Leistung. Die Methoden zur Gewichtung variieren: Manche Modelle nutzen exponentielle Abwertung, andere komplexere Ansätze, die die Spielbedingungen berücksichtigen.
Ein besonders interessanter Aspekt ist die Kombination von xG mit anderen Metriken. Ein gutes Vorhersagemodell nutzt xG nicht isoliert, sondern in Verbindung mit Faktoren wie Ballbesitz, Pressing-Intensität, Passgenauigkeit und anderen. Die Korrelationen zwischen diesen Variablen sind komplex, und die besten Machine-Learning-Modelle erkennen Muster, die für Menschen schwer zu erkennen sind.
Expected Goals in der Champions League
Die Champions League stellt besondere Anforderungen an xG-basierte Analysen. Der Wettbewerb bringt Teams aus verschiedenen Ligen zusammen, deren xG-Werte nicht direkt vergleichbar sind. Ein xG von 2,0 gegen einen Bundesliga-Absteiger hat eine andere Bedeutung als derselbe Wert gegen einen Premier-League-Spitzenreiter.
Das neue Format mit der Ligaphase verschärft dieses Problem. In der alten Gruppenphase spielte jedes Team sechsmal gegen dieselben drei Gegner, was eine gewisse Normierung ermöglichte. In der Ligaphase mit acht verschiedenen Gegnern pro Team ist die Vergleichbarkeit noch schwieriger. Die Gegnerqualität variiert stark, und ein naiver Vergleich der xG-Werte führt zu Fehlschlüssen.

Die Lösung liegt in der Berücksichtigung des Spielniveaus. Fortgeschrittene Modelle adjustieren die xG-Werte basierend auf der Stärke des Gegners. Ein hoher xG-Wert gegen einen schwachen Gegner wird abgewertet, ein niedriger Wert gegen einen starken Gegner aufgewertet. Diese Adjustment-Verfahren sind nicht trivial, weil sie wiederum auf Schätzungen der relativen Spielstärke beruhen, die selbst unsicher sind.
Ein weiterer Aspekt ist die unterschiedliche Intensität der Spiele. Champions-League-Partien sind in der Regel intensiver als durchschnittliche Ligaspiele, mit höherem Pressing, schnellerem Umschalten und weniger Raum für den Gegner. Das beeinflusst die Art der Chancen, die kreiert werden. Teams, die in ihrer Liga viele hochwertige Chancen erarbeiten, finden es in der Champions League möglicherweise schwerer, dasselbe Niveau zu erreichen.
Die defensive xG-Analyse ist in der Champions League besonders aufschlussreich. Während die Offensivstärke durch individuelle Klasse geprägt sein kann, zeigt die Defensive, wie gut eine Mannschaft organisiert ist und Räume schließt. Teams, die in der Liga niedrige xG-against-Werte haben, sind oft auch in Europa schwer zu bespielen, weil defensive Organisation weniger von der individuellen Gegnerqualität abhängt als offensive Durchschlagskraft.
Die Grenzen des xG-Modells
Bei aller Begeisterung für Expected Goals muss man die Grenzen der Metrik kennen. Kein statistisches Modell erfasst die Realität vollständig, und xG ist keine Ausnahme. Die Kenntnis dieser Limitationen ist wichtig, um die Aussagekraft von xG-basierten Vorhersagen richtig einzuschätzen.
Die offensichtlichste Grenze betrifft die individuelle Abschlussqualität. Das Standard-xG-Modell basiert auf dem Durchschnitt aller Spieler, aber manche Spieler sind überdurchschnittlich gute oder schlechte Abschließer. Ein Elfmeter hat einen xG-Wert von etwa 0,76 bis 0,79, aber ein Spieler wie Robert Lewandowski verwandelt deutlich mehr als 76 Prozent seiner Elfmeter, während andere Spieler unter diesem Durchschnitt liegen. Die besten xG-Modelle versuchen, diese individuellen Unterschiede zu berücksichtigen, aber eine vollständige Erfassung ist schwierig.
Die Torwartqualität ist ein verwandtes Problem. xG bewertet die Chance aus Sicht des Schützen, aber nicht alle Torwarte sind gleich gut. Ein Schuss mit xG 0,3 gegen einen Weltklasse-Keeper hat in Wahrheit eine niedrigere Torwahrscheinlichkeit als derselbe Schuss gegen einen durchschnittlichen Torwart. Einige Modelle versuchen, dies durch Torwart-spezifische Adjustierungen zu korrigieren, aber die Datenbasis für individuelle Torwartleistungen ist oft begrenzt.
Die Varianz bei kleinen Stichproben ist ein statistisches Problem, das oft unterschätzt wird. Ein einzelnes Spiel kann stark vom Erwartungswert abweichen, ohne dass das auf ein Problem mit der Analyse hindeutet. Wenn ein Team einen kumulierten xG von 2,5 hat und 0:0 endet, bedeutet das nicht, dass die xG-Berechnung falsch war. Es bedeutet, dass an diesem Tag die Torwahrscheinlichkeiten nicht eingetreten sind, was statistisch völlig normal ist. Erst über viele Spiele hinweg sollten die tatsächlichen Tore den erwarteten Toren entsprechen.
Ein subtileres Problem ist, dass xG nur Situationen erfasst, die zu einem Schuss führen. Eine Mannschaft, die viele gefährliche Situationen kreiert, aber im letzten Moment den falschen Pass spielt oder den Ball verliert, erscheint in der xG-Statistik schwächer als sie tatsächlich ist. Das Konzept der Expected Threat versucht, dieses Problem zu adressieren, indem es den Wert jeder Ballposition bewertet, nicht nur der Schüsse, aber es ist noch nicht so etabliert wie xG.
xG-basierte Wettstrategien
Für Nutzer von KI-Vorhersagen, die auf Basis von xG-Daten wetten möchten, gibt es einige strategische Überlegungen, die den Unterschied zwischen informiertem und blindem Wetten ausmachen können.
Die naheliegendste Anwendung betrifft Over/Under-Wetten auf die Torzahl. Wenn beide Teams hohe xG-Werte in ihren letzten Spielen haben, ist die Wahrscheinlichkeit höher, dass auch in ihrer Begegnung viele Tore fallen. Umgekehrt deutet ein niedriges xG auf beiden Seiten auf ein torarmes Spiel hin. Die Summe der erwarteten Tore beider Teams gibt einen Anhaltspunkt, ob Over oder Under wahrscheinlicher ist.
Allerdings ist die Sache komplizierter, als sie klingt. Die xG-Werte beider Teams wurden gegen andere Gegner erzielt, und die spezifische Konstellation kann anders aussehen. Ein Team mit hohem offensivem xG gegen eine Mannschaft mit niedrigem defensivem xG-against ist anders zu bewerten als dieselben Teams gegen andere Gegner. Die Interaktion der Spielstile ist ein Faktor, den einfache xG-Analysen oft nicht erfassen.

Die Identifikation von Über- und Unterperformance ist eine weitere strategische Anwendung. Teams, die konstant mehr Tore erzielen als ihr xG erwarten lässt, performen über Erwartung. Statistisch gesehen ist es wahrscheinlich, dass sie irgendwann zur Mittelwertregression neigen, also weniger Tore schießen werden. Umgekehrt werden Teams, die unter ihrem xG bleiben, wahrscheinlich irgendwann mehr Tore erzielen. Diese Erkenntnis kann für Wetten genutzt werden, wenn die Buchmacherquoten die Regression noch nicht vollständig einpreisen.
Both Teams to Score, im Deutschen oft als Beide Teams treffen bezeichnet, ist ein Wettmarkt, bei dem xG-Daten ebenfalls nützlich sind. Wenn beide Teams regelmäßig Chancen kreieren und selten zu Null spielen, ist BTTS wahrscheinlicher. Die defensiven xG-against-Werte geben Aufschluss darüber, wie oft eine Mannschaft hochwertige Chancen zulässt, was wiederum die Wahrscheinlichkeit beeinflusst, dass der Gegner trifft.
Praktische xG-Tools für die eigene Analyse
Wer xG-Daten selbst nutzen möchte, findet verschiedene Ressourcen, die kostenlos oder günstig zugänglich sind. Die Qualität und Tiefe der verfügbaren Daten variiert, aber für eine fundierte Analyse reicht das öffentlich Zugängliche in vielen Fällen aus.
Understat ist eine der bekanntesten Quellen für xG-Daten. Die Website bietet detaillierte Statistiken für die großen europäischen Ligen, aufgeschlüsselt nach Teams, Spielern und einzelnen Spielen. Man kann sehen, welche xG-Werte in einem bestimmten Spiel erzielt wurden, wo die Schüsse abgegeben wurden und wie das kumulative xG im Spielverlauf entwickelt hat. Die Daten reichen mehrere Jahre zurück, was Trendanalysen ermöglicht.
FBref, betrieben von Sports Reference, bietet ebenfalls umfassende xG-Daten, ergänzt durch eine Vielzahl anderer fortgeschrittener Metriken. Die Stärke von FBref liegt in der Breite der Daten und der Möglichkeit, verschiedene Statistiken zu kombinieren. Man kann beispielsweise sehen, wie sich das xG eines Teams zu seiner Pressing-Intensität verhält oder wie die Passgenauigkeit mit der Chancenqualität korreliert.
Die offiziellen UEFA-Statistiken für die Champions League enthalten mittlerweile ebenfalls xG-Werte. Diese Daten sind besonders relevant, weil sie auf denselben Berechnungsmethoden basieren, die auch für die offiziellen Übertragungsstatistiken verwendet werden. Für die Analyse von Champions-League-Spielen sind sie eine primäre Quelle.
Für die Interpretation der Daten ist es hilfreich, einige Richtwerte im Kopf zu haben. Ein durchschnittliches Bundesliga-Spiel hat einen kumulierten xG-Wert von etwa 2,5 bis 3,0. Werte über 3,5 deuten auf ein chancenreiches Spiel hin, Werte unter 2,0 auf ein taktisch geprägtes Match mit wenigen Chancen. In der Champions League sind die Werte tendenziell etwas niedriger, weil die Teams defensiv organisierter sind und die Gegnerqualität höher.
Die Zukunft von xG und verwandten Metriken
Expected Goals ist nicht das Ende der statistischen Evolution im Fußball, sondern ein Zwischenschritt. Die Forschung entwickelt kontinuierlich neue Metriken, die bestimmte Aspekte besser erfassen als xG, und die nächste Generation von KI-Vorhersagemodellen wird diese Entwicklungen integrieren.
Expected Threat, kurz xT, ist ein Beispiel für eine Weiterentwicklung. Statt nur Schüsse zu bewerten, analysiert xT den Wert jeder Ballposition auf dem Spielfeld. Ein Pass ins Mittelfeld hat einen anderen Bedrohungswert als ein Pass in den Strafraum. Diese Metrik erfasst den gesamten Aufbau des Spiels, nicht nur die finalen Aktionen, und kann helfen, Teams zu bewerten, die viel Gefahr erzeugen, aber im letzten Moment scheitern.
Expected Assists, kurz xA, bewertet die Qualität der Vorlagen unabhängig davon, ob sie zu einem Tor führen. Ein perfekter Pass in den Lauf des Stürmers hat einen hohen xA-Wert, auch wenn der Stürmer den Ball verstolpert. Diese Metrik ist nützlich, um die Kreativität von Spielmachern zu bewerten und Teams zu identifizieren, die gute Chancen herausspielen, aber an der Verwertung scheitern.
Post-Shot Expected Goals, bereits erwähnt, wird immer raffinierter. Moderne Modelle nutzen Computer-Vision-Technologie, um die exakte Flugbahn des Balls zu analysieren und daraus noch präzisere Torwahrscheinlichkeiten abzuleiten. Diese Daten sind noch nicht flächendeckend verfügbar, aber sie werden in den kommenden Jahren vermutlich zum Standard werden.
Für KI-Vorhersagen bedeutet diese Entwicklung, dass die Modelle kontinuierlich verfeinert werden. Was heute als fortgeschritten gilt, wird in fünf Jahren möglicherweise veraltet sein. Die Grundprinzipien aber bleiben: die Nutzung historischer Daten, um Wahrscheinlichkeiten zu berechnen, und die Integration dieser Wahrscheinlichkeiten in Prognosemodelle. Expected Goals war der erste große Schritt in diese Richtung, und es bleibt trotz aller Weiterentwicklungen das Fundament, auf dem moderne Fußballanalyse aufbaut.
Die Integration von xG in die eigene Analyse
Zum Abschluss einige Gedanken dazu, wie man xG-Daten sinnvoll in die eigene Analysepraxis integrieren kann. Die bloße Kenntnis der Metrik reicht nicht; es kommt darauf an, sie richtig anzuwenden.

Der erste Schritt ist, xG nicht isoliert zu betrachten. Eine Mannschaft mit hohem xG ist nicht automatisch besser als eine mit niedrigerem Wert. Die Kontextfaktoren zählen: Gegen wen wurden die Werte erzielt? Unter welchen Bedingungen? Wie konstant sind sie über Zeit? Die Zahl allein ist nur der Ausgangspunkt der Analyse, nicht ihr Ende.
Der zweite Schritt ist, xG mit anderen Informationen zu kombinieren. Aktuelle Verletzungen, taktische Anpassungen, die Bedeutung des Spiels für beide Teams sind Faktoren, die xG-Daten nicht erfassen. Eine kluge Analyse nutzt xG als quantitative Basis und ergänzt sie durch qualitative Einschätzungen.
Der dritte Schritt ist, die Unsicherheit anzuerkennen. Selbst ein perfektes xG-Modell würde keine exakten Vorhersagen liefern, weil Fußball inhärent unvorhersehbar ist. Die xG-Analyse verbessert die Einschätzung, aber sie eliminiert das Risiko nicht. Wer das versteht, geht realistischer an Prognosen heran und vermeidet die Falle, in eine einzelne Zahl zu viel Vertrauen zu setzen.
Expected Goals hat die Art verändert, wie wir über Fußball denken können. Es hat eine Sprache geschaffen, um Chancenqualität zu diskutieren, und ein Werkzeug, um Leistungen jenseits der reinen Ergebnisse zu bewerten. Für KI-Vorhersagen in der Champions League ist es ein unverzichtbares Element, das jedoch seine volle Kraft erst entfaltet, wenn es richtig verstanden und angewendet wird.