KI Champions League Vorhersage simuliert: 20.000 Spiele in Sekunden
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Es klingt wie Science-Fiction: Ein Computer spielt dasselbe Fußballspiel zwanzigtausend Mal durch, jedes Mal mit leicht anderen Verläufen, und fasst am Ende zusammen, welches Ergebnis am wahrscheinlichsten ist. Doch genau das passiert bei modernen KI-Vorhersagen, die auf Simulationen setzen. Die Methode heißt Monte-Carlo-Simulation, benannt nach dem berühmten Spielkasino, und sie ist eines der mächtigsten Werkzeuge der statistischen Analyse.
Der Grundgedanke ist bestechend: Statt zu versuchen, ein einzelnes Ergebnis vorherzusagen, spielt man alle möglichen Ergebnisse durch und schaut, welche am häufigsten auftreten. Das Fußballspiel wird zum Experiment, das virtuell beliebig oft wiederholt werden kann. Dabei berücksichtigt die Simulation den Zufall, der jedem realen Spiel innewohnt, und liefert am Ende nicht eine einzelne Prognose, sondern eine Verteilung von Wahrscheinlichkeiten.
Für die Champions League sind Simulationen besonders wertvoll. Der Wettbewerb mit seinem K.O.-Format und den vielen Unwägbarkeiten ist wie geschaffen für diese Methode. Wer verstehen will, was hinter den Prozentangaben von BETSiE und ähnlichen Systemen steckt, muss sich mit dem Prinzip der Simulation beschäftigen. Dieser Leitfaden erklärt, wie Monte-Carlo-Simulationen funktionieren, was sie leisten können und wo ihre Grenzen liegen.
Das Prinzip der Monte-Carlo-Simulation
Die Monte-Carlo-Methode wurde in den 1940er Jahren am Los Alamos National Laboratory entwickelt, ursprünglich für Berechnungen zur Atombombe. Die Wissenschaftler standen vor Problemen, die zu komplex waren, um sie analytisch zu lösen, und kamen auf die Idee, stattdessen den Zufall zu nutzen: Wenn man ein Problem nicht direkt lösen kann, kann man es vielleicht durch viele zufällige Versuche approximieren.
Das Prinzip lässt sich an einem einfachen Beispiel illustrieren. Angenommen, man möchte die Fläche eines Kreises berechnen, kennt aber die Formel nicht. Eine Monte-Carlo-Lösung wäre: Man zeichnet den Kreis in ein Quadrat, wirft zufällig Punkte auf das Quadrat und zählt, wie viele davon im Kreis landen. Das Verhältnis der Punkte im Kreis zu allen Punkten entspricht dem Verhältnis der Kreisfläche zur Quadratfläche. Je mehr Punkte man wirft, desto genauer wird die Schätzung.
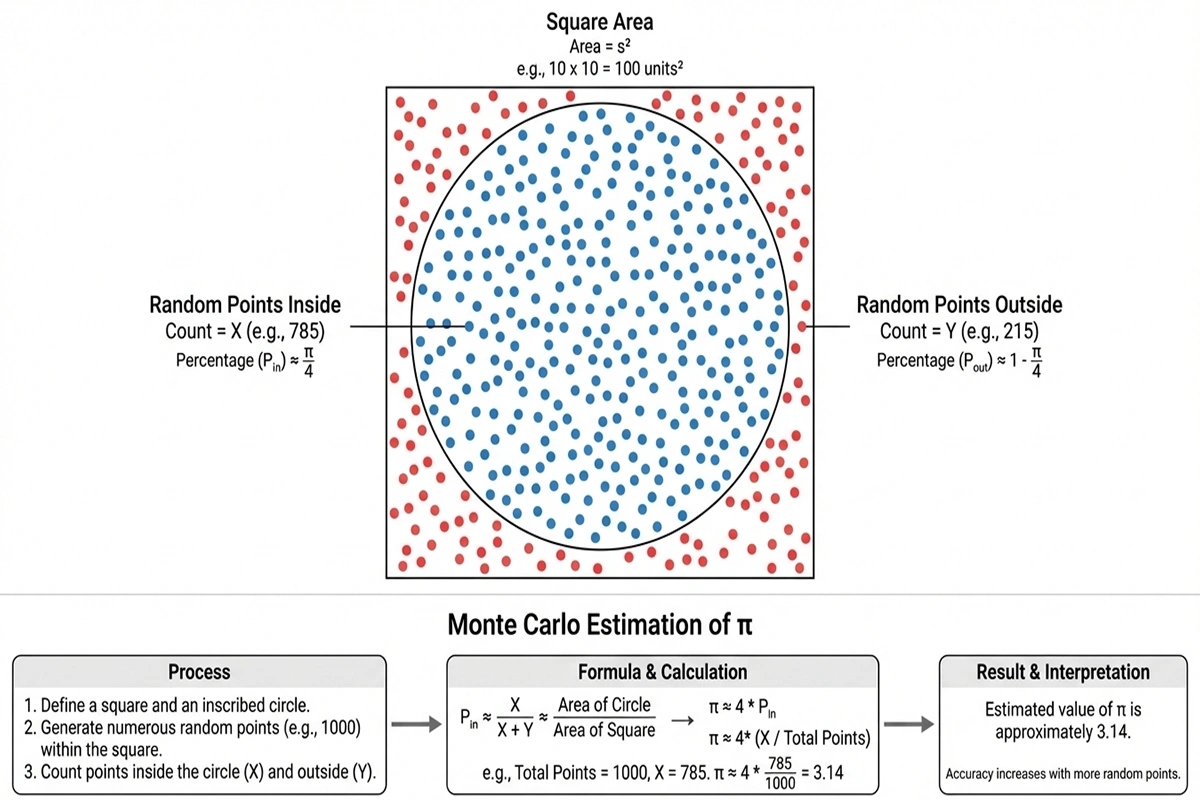
Für Fußballsimulationen funktioniert das Prinzip analog. Das Spiel wird nicht einmal, sondern tausende Male virtuell durchgespielt. Bei jedem Durchlauf werden Zufallselemente eingebaut: Ob ein Schuss trifft oder nicht, ob ein Pass ankommt oder abgefangen wird, ob ein Foul gepfiffen wird oder nicht. Diese Zufallselemente folgen Wahrscheinlichkeitsverteilungen, die aus historischen Daten abgeleitet wurden.
Nach vielen Durchläufen ergibt sich ein Bild der möglichen Ergebnisse. Vielleicht hat Team A in 55 Prozent der Simulationen gewonnen, in 25 Prozent unentschieden gespielt und in 20 Prozent verloren. Diese Verteilung ist die Grundlage der Prognose. Sie sagt nicht, was passieren wird, aber sie zeigt, was wie wahrscheinlich ist.
Die Anzahl der Simulationen ist entscheidend für die Genauigkeit. Bei hundert Durchläufen schwanken die Ergebnisse noch stark. Bei tausend werden sie stabiler. Bei zehntausend oder mehr konvergieren sie gegen stabile Werte. Professionelle Systeme wie BETSiE führen zwanzigtausend oder mehr Simulationen pro Spiel durch, um präzise Wahrscheinlichkeiten zu erhalten.
Was bei einer Spielsimulation passiert
Eine Fußballsimulation ist ein komplexes Modell, das versucht, die wesentlichen Aspekte eines Spiels abzubilden. Die Details variieren je nach System, aber die grundlegende Struktur ist ähnlich.
Das Spiel wird in diskrete Zeiteinheiten unterteilt, etwa in Minuten oder Fünf-Minuten-Blöcke. In jeder Einheit können verschiedene Ereignisse auftreten: Torchancen, Schüsse, Tore, Fouls, Karten und so weiter. Die Wahrscheinlichkeiten für diese Ereignisse werden aus den Daten beider Teams abgeleitet.
Torchancen sind das Herzstück der Simulation. Ihre Häufigkeit hängt von der Offensivstärke des angreifenden Teams und der Defensivstärke des verteidigenden Teams ab. Ein Team, das im Schnitt drei Großchancen pro Spiel herausspielt, wird in der Simulation entsprechend oft Chancen generieren, wobei die genaue Anzahl in jedem Durchlauf zufällig variiert.
Wenn eine Chance auftritt, wird simuliert, ob sie zu einem Tor führt. Hier kommt der xG-Wert ins Spiel. Jede Chance hat eine bestimmte Torwahrscheinlichkeit, und ein Zufallsgenerator entscheidet, ob der Schuss trifft. Eine Chance mit xG 0,3 führt in etwa 30 Prozent der Simulationen zu einem Tor.
Die Aggregation über das gesamte Spiel ergibt das Endergebnis. Wenn Team A in einem Durchlauf zwei Chancen mit xG 0,2 und eine mit xG 0,4 hatte und der Zufall entschied, dass die erste und dritte trafen, steht es 2:0. Im nächsten Durchlauf könnten dieselben Chancen anders ausgehen, und das Ergebnis wäre 1:0 oder 0:0.
Fortgeschrittene Simulationen berücksichtigen zusätzliche Faktoren. Der Spielverlauf kann die Taktik beeinflussen: Ein Team, das in Führung liegt, spielt möglicherweise defensiver. Platzverweise ändern die Kräfteverhältnisse. Einwechslungen bringen frische Kräfte. Manche Modelle versuchen, all diese Dynamiken abzubilden, was die Komplexität erhöht, aber auch die Realitätsnähe verbessern kann.
BETSiE und professionelle Simulationssysteme
BETSiE, der Supercomputer der Wettbasis, ist eines der bekanntesten Simulationssysteme im deutschsprachigen Raum. Der Name steht für Betting Simulation Intelligence Engine, und das System führt für jedes analysierte Spiel etwa zwanzigtausend Simulationen durch.

Die Funktionsweise von BETSiE illustriert, wie professionelle Systeme arbeiten. Zunächst werden alle verfügbaren Daten gesammelt: historische Ergebnisse, aktuelle Form, xG-Werte, Kadersituation, Heim- und Auswärtsstärke und viele weitere Faktoren. Diese Daten fließen in ein Modell, das die Parameter der Simulation bestimmt.
Dann beginnt die eigentliche Simulation. Zwanzigtausend Mal wird das Spiel virtuell durchgespielt, jedes Mal mit anderen Zufallsverläufen. Die Ergebnisse werden protokolliert und am Ende aggregiert. Das Resultat ist eine Wahrscheinlichkeitsverteilung: 48 Prozent Heimsieg, 27 Prozent Unentschieden, 25 Prozent Auswärtssieg, zum Beispiel.
Der Unterschied zwischen einfachen und komplexen Modellen liegt in den Details. Ein einfaches Modell simuliert vielleicht nur die Tore auf Basis aggregierter xG-Werte. Ein komplexes Modell kann einzelne Spieler modellieren, taktische Formationen berücksichtigen, den Einfluss von Verletzungen quantifizieren und die Dynamik des Spielverlaufs abbilden.
Professionelle Systeme integrieren oft zusätzliche Informationen, die über reine Spielstatistiken hinausgehen. Wetterbedingungen, Reisestrapazen, Bedeutung des Spiels für beide Teams, historische Rivalitäten: All diese Faktoren können die Wahrscheinlichkeiten beeinflussen und werden in anspruchsvollen Modellen berücksichtigt.
Die Rechenleistung moderner Computer macht es möglich, extrem umfangreiche Simulationen in kurzer Zeit durchzuführen. Was in den 1940er Jahren Wochen gedauert hätte, geschieht heute in Sekunden. Diese Geschwindigkeit ermöglicht nicht nur mehr Durchläufe, sondern auch häufigere Aktualisierungen: Wenn sich die Datenlage ändert, etwa durch eine Verletzungsmeldung, können die Simulationen sofort neu berechnet werden.
Die Aussagekraft von Simulationsergebnissen
Das wichtigste Missverständnis über Simulationen betrifft ihre Interpretation. Eine Siegwahrscheinlichkeit von 52 Prozent bedeutet nicht, dass das Team wahrscheinlich gewinnt. Sie bedeutet, dass das Team in etwas mehr als der Hälfte aller simulierten Fälle gewonnen hat. Das klingt ähnlich, ist aber ein wesentlicher Unterschied.
Bei einer Wahrscheinlichkeit von 52 zu 48 ist das Ergebnis praktisch offen. Die Simulation sagt: Beide Ausgänge sind fast gleich wahrscheinlich. Das ist keine Prognose, sondern eine Beschreibung von Unsicherheit. Erst bei deutlicheren Unterschieden, etwa 70 zu 30, lässt sich von einem klaren Favoriten sprechen, aber auch dann bleibt ein beträchtliches Risiko.
Konfidenzintervalle sind ein Konzept, das hilft, die Unsicherheit zu quantifizieren. Sie geben an, in welchem Bereich die wahre Wahrscheinlichkeit mit einer bestimmten Sicherheit liegt. Wenn ein System eine Siegwahrscheinlichkeit von 55 Prozent mit einem 95-Prozent-Konfidenzintervall von 50 bis 60 Prozent angibt, bedeutet das: Die wahre Wahrscheinlichkeit liegt mit 95-prozentiger Sicherheit irgendwo zwischen 50 und 60 Prozent.
Der Unterschied zwischen Simulation und Vorhersage ist fundamental. Eine Simulation beschreibt, was passieren könnte und mit welcher Häufigkeit. Eine Vorhersage sagt, was passieren wird. Simulationen machen keine Vorhersagen im engeren Sinne. Sie liefern Wahrscheinlichkeitsverteilungen, aus denen man Schlüsse ziehen kann, aber die Entscheidung, wie man diese Informationen nutzt, liegt beim Menschen.
Die Qualität einer Simulation hängt von der Qualität des zugrunde liegenden Modells ab. Wenn das Modell wichtige Faktoren nicht berücksichtigt oder die Daten fehlerhaft sind, werden auch zwanzigtausend Durchläufe kein zuverlässiges Ergebnis liefern. Die Simulation verstärkt die Eigenschaften des Modells, sie korrigiert sie nicht.
Sensitivitätsanalysen und Robustheit
Ein fortgeschrittener Aspekt der Simulationsarbeit ist die Sensitivitätsanalyse. Sie untersucht, wie stark das Ergebnis von einzelnen Parametern abhängt und wie robust die Prognosen sind.
Die Grundfrage lautet: Was passiert, wenn ich einen Parameter leicht verändere? Wenn der xG-Wert eines Teams von 1,5 auf 1,6 erhöht wird, ändert sich dann die Siegwahrscheinlichkeit um ein Prozent oder um zehn? Wenn kleine Änderungen große Auswirkungen haben, ist das ein Zeichen dafür, dass das Ergebnis auf wackligem Fundament steht.

Professionelle Systeme führen systematische Sensitivitätsanalysen durch. Sie variieren jeden Parameter in einem definierten Bereich und beobachten, wie sich die Ergebnisse ändern. Das Resultat ist ein Gefühl dafür, welche Faktoren wirklich entscheidend sind und wo Unsicherheiten lauern.
Für die Champions League ist das besonders relevant, weil viele Parameter unsicher sind. Der Heimvorteil ist in europäischen Spielen anders als in der Liga. Die Gegnerstärke ist schwer zu kalibrieren, wenn Teams aus verschiedenen Wettbewerben aufeinandertreffen. Die Form kann sich schnell ändern. All diese Unsicherheiten fließen in die Sensitivitätsanalyse ein.
Die Robustheit einer Prognose zeigt sich daran, wie stabil sie unter verschiedenen Annahmen bleibt. Wenn Bayern gegen Barcelona in neunzig Prozent aller Parametervariationen als Favorit erscheint, ist das robuster als wenn der Favoritenstatus nur bei einer bestimmten Parametereinstellung gilt.
Nutzer von KI-Prognosen sollten sich fragen, ob die Anbieter solche Analysen durchführen und kommunizieren. Ein System, das nur eine Punktschätzung liefert, ohne die Unsicherheit zu quantifizieren, ist weniger vertrauenswürdig als eines, das die Bandbreite möglicher Ergebnisse darstellt.
Turniersimulationen für die Champions League
Besonders interessant wird die Monte-Carlo-Methode, wenn man nicht einzelne Spiele, sondern ganze Turniere simuliert. Für die Champions League bedeutet das: Die Simulation spielt nicht nur ein Spiel durch, sondern die gesamte Ligaphase, die Playoffs und alle K.O.-Runden bis zum Finale.
Die Grundidee ist dieselbe wie bei Einzelspielen. Jedes Match wird simuliert, das Ergebnis beeinflusst die Tabelle oder das Weiterkommen, und am Ende steht ein Sieger. Bei tausenden Durchläufen des gesamten Turniers zeigt sich, welche Teams wie oft den Pokal gewonnen haben.
Die Herausforderung liegt in der kumulativen Unsicherheit. Bei einem einzelnen Spiel zwischen zwei Teams mag die Wahrscheinlichkeit noch relativ präzise sein. Aber wenn dieser Sieger dann gegen einen anderen Sieger spielt und so weiter, multiplizieren sich die Unsicherheiten. Bis zum Finale haben sich so viele Zufallselemente akkumuliert, dass selbst scheinbar klare Favoriten in vielen Simulationen ausscheiden.
Das neue Format der Champions League mit 36 Teams in der Ligaphase macht Turniersimulationen noch komplexer. Die Anzahl der möglichen Konstellationen ist enorm. Wer am Ende auf welchem Platz steht und welche K.O.-Paarungen sich ergeben, hängt von unzähligen Faktoren ab, die alle in die Simulation einfließen müssen.
Die Ergebnisse von Turniersimulationen werden oft als Prozentangaben für den Titelgewinn präsentiert. Real Madrid 18 Prozent, Manchester City 15 Prozent, Bayern 12 Prozent: So könnte eine typische Verteilung aussehen. Diese Zahlen zeigen, dass selbst der Favorit in mehr als vier von fünf Simulationen nicht Sieger wird. Das ist keine Schwäche der Simulation, sondern eine akkurate Darstellung der Realität: In K.O.-Turnieren kann viel passieren.
Die Tücken bei Bracket-Prognosen liegen im Losglück und in den matchspezifischen Faktoren. Manche Teams liegen einander nicht, unabhängig von ihrer allgemeinen Stärke. Ein Außenseiter kann gegen genau den Favoriten besonders gut aussehen, gegen den er im Viertelfinale gelost wird. Solche Feinheiten versuchen fortgeschrittene Simulationen zu erfassen, aber vollständig gelingt das nie.
Simulationen für die eigene Analyse nutzen
Wer selbst mit Simulationen arbeiten möchte, findet verschiedene Möglichkeiten, von einfachen Online-Tools bis hin zu selbst programmierten Modellen.
Im einfachsten Fall gibt es Webseiten, die Simulationen für einzelne Spiele anbieten. Man wählt zwei Teams, gibt vielleicht noch einige Parameter ein, und erhält eine Wahrscheinlichkeitsverteilung. Diese Tools sind praktisch für einen schnellen Überblick, aber ihre Methodik ist oft nicht transparent, und die Qualität variiert.
Für technisch versierte Nutzer bieten sich Programmiersprachen wie Python an. Mit relativ wenig Code lässt sich eine einfache Monte-Carlo-Simulation bauen. Man definiert die Torwahrscheinlichkeiten beider Teams, simuliert tausend Spiele und zählt die Ergebnisse. Das Ergebnis ist nicht so ausgefeilt wie bei professionellen Systemen, aber es vermittelt ein Gefühl für die Methode und ermöglicht eigene Experimente.
Die Interpretation der Ergebnisse ist der wichtigste Schritt. Eine Simulation liefert Zahlen, aber keine Handlungsanweisungen. Die Frage, ob eine Wette auf Basis einer bestimmten Wahrscheinlichkeit sinnvoll ist, hängt von den Quoten und der eigenen Risikobereitschaft ab. Die Simulation informiert die Entscheidung, sie trifft sie nicht.
Die Kombination mit anderen Analysemethoden erhöht den Wert. Simulationen allein berücksichtigen nur die Faktoren, die im Modell enthalten sind. Aktuelle Informationen, die noch nicht in den Daten stecken, muss der Nutzer selbst einbeziehen. Eine Verletzungsmeldung am Spieltag ändert die Wahrscheinlichkeiten, auch wenn die Simulation davon noch nichts weiß.
Ein realistisches Bild der eigenen Fähigkeiten ist wichtig. Professionelle Systeme wie BETSiE haben Zugang zu umfangreichen Daten, ausgefeilten Modellen und Jahren von Entwicklungsarbeit. Ein selbstgebautes Modell wird damit nicht konkurrieren können. Aber es kann helfen, die Logik zu verstehen und eine kritische Perspektive zu entwickeln.
Ein praktisches Beispiel: Simulation eines CL-Spiels
Um die abstrakte Theorie greifbarer zu machen, gehen wir ein konkretes Beispiel durch. Angenommen, wir wollen das Spiel zwischen Borussia Dortmund und Paris Saint-Germain simulieren.
Der erste Schritt ist die Datensammlung. Dortmund hat in den letzten zehn Spielen einen durchschnittlichen xG von 1,8, PSG von 2,1. Die Heimstärke von Dortmund ist ausgeprägt, ihr Heim-xG liegt bei 2,0. PSG hat auswärts einen xG von 1,7. Nach Berücksichtigung des Heimvorteils und der Gegnerstärke setzen wir Erwartungswerte von 1,5 für Dortmund und 1,6 für PSG an.
Nun beginnt die Simulation. In jedem Durchlauf generieren wir Tore für beide Teams basierend auf der Poisson-Verteilung mit den jeweiligen Erwartungswerten. Im ersten Durchlauf erzielt Dortmund zwei Tore, PSG eines: 2:1. Im zweiten Durchlauf schießt Dortmund null Tore, PSG zwei: 0:2. Und so weiter.
Nach tausend Durchläufen zählen wir die Ergebnisse. Vielleicht hat Dortmund 380 Mal gewonnen, PSG 400 Mal, und 220 Spiele endeten unentschieden. Das ergibt Wahrscheinlichkeiten von 38 Prozent, 40 Prozent und 22 Prozent. Ein sehr enges Spiel, bei dem PSG leicht favorisiert ist.

Die Verteilung der Ergebnisse ist aufschlussreich. Das häufigste Einzelergebnis ist vielleicht 1:1, gefolgt von 1:0 und 0:1. Ein 3:3 ist möglich, aber selten. Die Simulation zeigt auch, wie wahrscheinlich ein torreiches Spiel ist: Over 2,5 Tore tritt in etwa 55 Prozent der Durchläufe ein.
Diese einfache Simulation hat Grenzen. Sie berücksichtigt nicht die taktische Aufstellung, die individuelle Qualität der Spieler oder die Bedeutung des Spiels. Ein professionelles System würde all das einbeziehen. Aber selbst die einfache Version vermittelt ein Gefühl für die Bandbreite möglicher Ergebnisse.
Die Grenzen der Simulation
Bei aller Eleganz der Monte-Carlo-Methode ist es wichtig, ihre Grenzen zu kennen. Simulationen sind mächtige Werkzeuge, aber sie sind nicht unfehlbar.
Die fundamentale Grenze ist das Modell selbst. Eine Simulation kann nur das berücksichtigen, was in das Modell eingeht. Wenn ein Faktor nicht modelliert ist, etwa die psychologische Verfassung eines Spielers oder ein taktischer Kniff des Trainers, wird er in der Simulation nicht abgebildet. Das Ergebnis ist nur so gut wie die Eingaben.
Die Kalibrierung der Wahrscheinlichkeiten ist eine weitere Herausforderung. Woher weiß man, dass eine Chance mit xG 0,3 tatsächlich in 30 Prozent der Fälle zu einem Tor führt? Diese Werte stammen aus historischen Daten, aber die Vergangenheit ist nicht immer ein guter Leitfaden für die Zukunft. Spieler verbessern sich, Taktiken ändern sich, und was gestern galt, muss morgen nicht mehr stimmen.
Der Zufall in der Simulation ist kontrolliert, aber der Zufall im echten Fußball ist es nicht. Eine Simulation kann einen Pfostenschuss modellieren, aber nicht den exakten Winkel, in dem der Ball abprallt. Sie kann eine Verletzung als Wahrscheinlichkeit einbeziehen, aber nicht den spezifischen Moment, in dem sie passiert. Die Realität ist immer reicher als das Modell.
Ein oft übersehener Aspekt ist die Korrelation zwischen Ereignissen. In einer einfachen Simulation fallen Tore unabhängig voneinander. Im echten Fußball gibt es aber Wechselwirkungen: Ein frühes Gegentor kann ein Team verunsichern und zu weiteren Gegentoren führen. Ein Führungstreffer kann das gegnerische Team zu riskanten Angriffen zwingen, die Konterchancen eröffnen. Diese Dynamiken vollständig zu modellieren ist extrem schwierig.
Schließlich gibt es das Problem der Überinterpretation. Wenn eine Simulation 54 zu 46 ergibt, bedeutet das nicht, dass das erste Team gewinnen wird. Es bedeutet nicht einmal, dass es der wahrscheinlichere Sieger ist, jedenfalls nicht in einem praktisch relevanten Sinne. Der Unterschied ist so gering, dass er im Bereich der Modellunsicherheit liegt. Seriöse Nutzer von Simulationen wissen, dass kleine Unterschiede keine großen Aussagen rechtfertigen.
Die Zukunft der Simulationstechnologie
Die Monte-Carlo-Simulation ist eine etablierte Methode, aber sie entwickelt sich weiter. Neue Datenquellen, leistungsfähigere Computer und fortschrittlichere Modelle versprechen genauere Prognosen.
Eine Entwicklung ist die Integration von Tracking-Daten in Simulationen. Moderne Stadien erfassen die Position jedes Spielers mehrmals pro Sekunde. Diese Daten ermöglichen eine viel feinere Modellierung des Spiels: Wo entstehen Lücken in der Abwehr? Wie schnell schaltet ein Team um? Welche Laufwege sind typisch für bestimmte Spielzüge?
Machine Learning erweitert die Möglichkeiten der Simulation. Anstatt die Parameter des Modells manuell festzulegen, können Algorithmen sie aus den Daten lernen. Das Ergebnis sind Modelle, die Muster erkennen, die menschlichen Analysten verborgen bleiben.
Die Echtzeitanpassung von Simulationen ist ein weiterer Trend. Statt vor dem Spiel eine Prognose zu erstellen und dabei zu bleiben, können moderne Systeme ihre Einschätzungen während des Spiels aktualisieren. Jedes Ereignis, jedes Tor, jede Karte fließt in eine neue Simulation ein, die die verbleibenden Minuten prognostiziert.
Die Cloud-Technologie demokratisiert den Zugang zu Simulationskapazitäten. Was früher teure Spezialhardware erforderte, kann heute über Cloud-Dienste gemietet werden. Das ermöglicht auch kleineren Anbietern und Einzelpersonen, aufwendige Simulationen durchzuführen.
Die Integration verschiedener Datenquellen wird immer wichtiger. Simulationen, die nicht nur Spielstatistiken, sondern auch Social-Media-Sentiment, Wetterdaten, Sportwissenschaft und andere Faktoren einbeziehen, könnten genauere Prognosen liefern. Die Herausforderung liegt darin, relevante von irrelevanten Daten zu unterscheiden.
Für Nutzer bedeutet diese Entwicklung vor allem eines: Die Werkzeuge werden besser, aber die Grundprinzipien bleiben. Simulationen sind und bleiben ein Mittel, um mit Unsicherheit umzugehen. Sie eliminieren den Zufall nicht, sie quantifizieren ihn. Und in einem Sport wie Fußball, wo das Unvorhersehbare zum Wesen gehört, ist das ein wertvoller Beitrag.
Das Verständnis für die Methode macht den Unterschied zwischen blindem Vertrauen und informierter Nutzung. Wer weiß, was hinter den Zahlen steckt, kann sie besser einordnen, ihre Grenzen erkennen und klügere Entscheidungen treffen. Die zwanzigtausend simulierten Spiele sind kein Orakel, aber sie sind ein mächtiges Werkzeug für alle, die es richtig zu nutzen wissen.