KI Champions League Vorhersage statistisch: Die Mathematik hinter dem Tipp
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Wer sich ernsthaft mit KI-Vorhersagen für die Champions League beschäftigt, stößt unweigerlich auf eine Wahrheit, die manche überrascht: Hinter den Prognosen steckt keine Magie, sondern Mathematik. Statistische Methoden bilden das Fundament, auf dem alle seriösen Vorhersagemodelle aufbauen. Statistische Vorhersagen bei KI Champions League Vorhersage. Die Algorithmen mögen komplex sein, die neuronalen Netze verschachtelt, aber am Ende läuft alles auf Zahlen, Wahrscheinlichkeiten und statistische Verteilungen hinaus.
Das ist keine Schwäche, sondern eine Stärke. Statistische Methoden sind transparent, überprüfbar und reproduzierbar. Sie liefern keine Garantien, aber sie machen die Unsicherheit quantifizierbar. Wer versteht, wie die Statistik hinter den Prognosen funktioniert, kann die Ergebnisse besser einordnen, ihre Grenzen erkennen und klügere Entscheidungen treffen.
Dieser Leitfaden nimmt die statistischen Grundlagen unter die Lupe, die modernen KI-Vorhersagen zugrunde liegen. Von der Wahrscheinlichkeitstheorie über die Poisson-Verteilung bis zu Elo-Ratings und Regressionsanalysen werden die wichtigsten Konzepte erklärt, und zwar so, dass auch Leser ohne mathematischen Hintergrund folgen können. Das Ziel ist nicht, aus jedem einen Statistiker zu machen, sondern ein Verständnis zu vermitteln, das die Nutzung von KI-Prognosen verbessert.
Wahrscheinlichkeitstheorie im Fußballkontext
Bevor wir in die spezifischen Methoden eintauchen, lohnt sich ein Blick auf das Fundament: die Wahrscheinlichkeitstheorie. Lesen Sie auch Vorhersagen mit Wahrscheinlichkeit. Sie ist die Sprache, in der alle statistischen Vorhersagen formuliert werden, und ihr Verständnis ist der Schlüssel zur richtigen Interpretation von Prognosen.
Eine Wahrscheinlichkeit ist ein Wert zwischen null und eins, der angibt, wie wahrscheinlich ein bestimmtes Ereignis ist. Null bedeutet unmöglich, eins bedeutet sicher. Ein Wert von 0,6 oder 60 Prozent sagt aus, dass das Ereignis in sechs von zehn gleichartigen Situationen eintreten würde. Das ist eine wichtige Nuance: Wahrscheinlichkeiten beziehen sich nicht auf einzelne Ereignisse, sondern auf die relative Häufigkeit bei vielen Wiederholungen.
Für den Fußball bedeutet das: Wenn ein KI-System dem FC Bayern eine Siegwahrscheinlichkeit von 70 Prozent gegen einen Gegner gibt, heißt das nicht, dass Bayern definitiv gewinnen wird. Es heißt, dass Bayern in einer gedachten Serie von hundert identischen Spielen siebzigmal gewinnen würde. Die restlichen dreißig Spiele würden mit Unentschieden oder Niederlagen enden. Das eine konkrete Spiel, das tatsächlich stattfindet, kann jedes dieser Ergebnisse haben.
Der Erwartungswert ist ein verwandtes Konzept, das bei Fußballprognosen häufig auftaucht. Er gibt den durchschnittlichen Wert an, den eine Variable bei vielen Wiederholungen annehmen würde. Die erwarteten Tore einer Mannschaft, also der xG-Wert, sind ein Erwartungswert: Der Durchschnitt aller Tore, die bei vielen Wiederholungen der gegebenen Chancen erzielt würden.
Die Standardabweichung misst, wie stark die tatsächlichen Werte typischerweise vom Erwartungswert abweichen. Eine niedrige Standardabweichung bedeutet, dass die Ergebnisse eng um den Durchschnitt streuen. Eine hohe Standardabweichung zeigt große Schwankungen an. Im Fußball ist die Standardabweichung bei der Torzahl relativ hoch im Verhältnis zum Erwartungswert, was bedeutet, dass Überraschungen häufig sind.
Die Normalverteilung, oft als Glockenkurve dargestellt, beschreibt, wie viele statistische Phänomene verteilt sind. Bei Fußballergebnissen ist die Verteilung allerdings nicht normal, weil Tore diskrete Ereignisse sind und nicht negativ werden können. Hier kommt eine andere Verteilung ins Spiel, die wir gleich genauer betrachten werden.
Die Poisson-Verteilung als Tor-Orakel
Wenn es eine statistische Verteilung gibt, die für Fußballprognosen wie geschaffen ist, dann ist es die Poisson-Verteilung. Sie wurde im 19. Jahrhundert entwickelt, um seltene, unabhängige Ereignisse zu modellieren, und genau das sind Tore in einem Fußballspiel.
Die Poisson-Verteilung beschreibt die Wahrscheinlichkeit, dass eine bestimmte Anzahl von Ereignissen in einem festen Zeitraum auftritt, wenn diese Ereignisse unabhängig voneinander und mit konstanter Rate eintreten. Ein Fußballspiel dauert 90 Minuten, Tore fallen relativ selten und weitgehend unabhängig voneinander. Die Annahmen passen.
Der einzige Parameter, den die Poisson-Verteilung benötigt, ist der Erwartungswert, also die durchschnittliche Anzahl von Ereignissen. Für ein Fußballspiel wäre das die erwartete Torzahl einer Mannschaft. Wenn der FC Bayern einen Erwartungswert von 2,1 Toren gegen einen bestimmten Gegner hat, liefert die Poisson-Verteilung die Wahrscheinlichkeiten für null, eins, zwei, drei oder mehr Tore.
Die Berechnung funktioniert nach einer Formel, die hier der Verständlichkeit halber in Worten beschrieben wird. Die Wahrscheinlichkeit für genau k Tore ist: der Erwartungswert hoch k, multipliziert mit der Euler-Zahl hoch minus dem Erwartungswert, geteilt durch die Fakultät von k. Das klingt kompliziert, aber in der Praxis berechnen Computer diese Werte in Sekundenbruchteilen.
Ein praktisches Beispiel: Bayern hat einen Erwartungswert von 2,0 Toren. Die Poisson-Verteilung ergibt dann etwa 13,5 Prozent Wahrscheinlichkeit für null Tore, 27,1 Prozent für ein Tor, 27,1 Prozent für zwei Tore, 18,0 Prozent für drei Tore, 9,0 Prozent für vier Tore, und die restlichen Prozent verteilen sich auf fünf oder mehr Tore. Diese Verteilung zeigt, dass das Ergebnis trotz eines klaren Erwartungswerts breit streuen kann.
Für eine vollständige Spielprognose braucht man die Verteilungen beider Teams. Wenn der Gegner einen Erwartungswert von 0,8 Toren hat, kann man analog seine Verteilung berechnen. Die Kombination beider Verteilungen ergibt die Wahrscheinlichkeiten für alle möglichen Endergebnisse: 1:0, 2:1, 0:0, und so weiter. Daraus lässt sich dann die Siegwahrscheinlichkeit für jedes Team und die Wahrscheinlichkeit eines Unentschiedens ableiten.
Die Grenzen der Poisson-Verteilung im Fußball sind bekannt. Sie nimmt an, dass Tore unabhängig voneinander fallen, was nicht ganz stimmt: Ein frühes Tor kann das Spielverhalten beider Teams verändern. Außerdem ist die Rate nicht konstant über das Spiel: In den Schlussminuten fallen überproportional viele Tore. Trotz dieser Einschränkungen bleibt Poisson das Arbeitspferd der Fußballstatistik.
Regressionsanalysen für Fußballprognosen
Während die Poisson-Verteilung die Torzahlen modelliert, stellt sich die Frage, woher die Erwartungswerte kommen. Hier kommen Regressionsanalysen ins Spiel, eine der mächtigsten Methoden der Statistik.
Die Grundidee der Regression ist, den Zusammenhang zwischen einer abhängigen Variable und einer oder mehreren unabhängigen Variablen zu modellieren. Im Fußballkontext könnte die abhängige Variable das Spielergebnis oder die Torzahl sein, und die unabhängigen Variablen wären Faktoren wie Heimvorteil, Tabellenposition, aktuelle Form, xG der letzten Spiele und andere.
Die lineare Regression ist die einfachste Form. Sie nimmt an, dass der Zusammenhang zwischen den Variablen linear ist: Mehr von X führt zu proportional mehr oder weniger von Y. Im Fußball kann das für bestimmte Zusammenhänge funktionieren, etwa zwischen xG und tatsächlich erzielten Toren über eine ganze Saison. Für komplexere Vorhersagen ist die lineare Regression allerdings oft zu simpel.
Die logistische Regression ist besser geeignet, wenn das Ergebnis binär ist: Sieg oder Niederlage, Tor oder kein Tor. Sie modelliert die Wahrscheinlichkeit eines Ereignisses als Funktion der unabhängigen Variablen. In der Praxis wird sie häufig für die Vorhersage von Spielausgängen verwendet, wobei der Output eine Wahrscheinlichkeit zwischen null und eins ist.
Die Auswahl der Variablen ist entscheidend für die Qualität einer Regression. Nicht alle Faktoren, die intuitiv relevant erscheinen, haben tatsächlich einen statistisch signifikanten Einfluss. Die Kunst besteht darin, die Variablen zu identifizieren, die wirklich prädiktiv sind, und diejenigen auszuschließen, die nur Rauschen hinzufügen.
Ein Problem, das in der Fußballanalyse häufig auftritt, ist die Multikollinearität. Das bedeutet, dass mehrere unabhängige Variablen miteinander korreliert sind. Zum Beispiel sind xG und Torschüsse hochkorreliert, weil Teams, die viele Torschüsse abgeben, tendenziell auch einen höheren xG-Wert haben. Wenn beide Variablen in dieselbe Regression eingehen, kann das zu instabilen Schätzungen führen. Die Lösung besteht darin, nur eine der korrelierten Variablen zu verwenden oder spezielle Methoden anzuwenden, die mit Multikollinearität umgehen können.
Elo-Rating-Systeme im Fußball
Das Elo-System hat eine interessante Geschichte. Es wurde ursprünglich vom Physiker Arpad Elo entwickelt, um die relative Spielstärke von Schachspielern zu messen. Die Grundidee ist bestechend einfach: Jeder Spieler oder jede Mannschaft hat einen Zahlenwert, der ihre Stärke repräsentiert. Nach jedem Spiel werden die Werte angepasst, basierend auf dem Ergebnis und der Differenz der Ratings vor dem Spiel.
Die Übernahme ins Fußball funktioniert mit einigen Modifikationen. Jede Mannschaft startet mit einem Basisrating, typischerweise 1500. Wenn eine Mannschaft ein Spiel gewinnt, gewinnt sie Punkte, der Verlierer gibt Punkte ab. Die Höhe der übertragenen Punkte hängt davon ab, wie überraschend das Ergebnis war: Ein Sieg eines schwächer eingestuften Teams gegen ein stärker eingestuftes führt zu einem größeren Punktetransfer als ein erwarteter Sieg des Favoriten.
Die Mathematik dahinter basiert auf der logistischen Funktion. Aus der Differenz der Elo-Werte wird eine erwartete Siegwahrscheinlichkeit berechnet. Eine Differenz von 400 Punkten entspricht einer erwarteten Quote von etwa 10:1 für das stärkere Team. Nach dem Spiel wird die tatsächliche mit der erwarteten Leistung verglichen, und die Ratings werden entsprechend angepasst.
Für die Champions League ist das Elo-System besonders nützlich, weil es eine einheitliche Skala für Teams aus verschiedenen Ligen liefert. Ein deutsches Team kann mit einem spanischen verglichen werden, obwohl sie nie direkt gegeneinander gespielt haben, solange beide gegen gemeinsame Gegner angetreten sind, deren Elo-Werte bekannt sind.
Die Vorteile des Elo-Systems liegen in seiner Einfachheit und Robustheit. Es passt sich automatisch an Leistungsänderungen an, es ist transparent und nachvollziehbar, und es benötigt keine komplexen Eingabedaten. Die Nachteile sind, dass es nur das Ergebnis berücksichtigt, nicht die Spielweise, und dass es kurzfristige Schwankungen nicht gut erfasst, weil die Ratings sich nur langsam ändern.
Verschiedene Anbieter haben ihre eigenen Elo-Varianten entwickelt, die zusätzliche Faktoren wie Tordifferenz, Heimvorteil und Bedeutung des Spiels einbeziehen. FiveThirtyEight zum Beispiel nutzt ein Elo-basiertes System für Fußballprognosen, das diese Erweiterungen integriert. Die Grundstruktur bleibt aber dieselbe: Eine Zahl pro Team, die sich nach jedem Spiel anpasst.
Statistische Signifikanz und Stichprobengrößen
Ein Konzept, das bei der Interpretation von Fußballstatistiken oft vernachlässigt wird, ist die statistische Signifikanz. Die Frage ist nicht nur, ob ein Muster in den Daten erkennbar ist, sondern auch, ob dieses Muster zufällig entstanden sein könnte.
Die zentrale Einsicht ist: Bei kleinen Stichproben sind Schwankungen normal und sagen wenig aus. Ein Team, das in drei Spielen dreimal verloren hat, muss nicht zwingend schlecht sein. Es könnte auch Pech gehabt haben. Umgekehrt beweist ein Team, das drei Spiele gewonnen hat, damit noch nicht, dass es besser ist als der Durchschnitt.
Die Faustregel in der Statistik lautet, dass man für belastbare Aussagen mindestens 30 Beobachtungen braucht. Im Fußball bedeutet das: Mindestens 30 Spiele, bevor man von einem stabilen Muster sprechen kann. Die Ligaphase der Champions League umfasst aber nur acht Spiele pro Team. Das ist viel zu wenig, um aus den CL-Ergebnissen allein zuverlässige Schlüsse zu ziehen.
Die Lösung besteht darin, zusätzliche Daten heranzuziehen. Die Ligaspiele desselben Teams erhöhen die Stichprobengröße. Die historischen Daten vergangener Saisons können ebenfalls einfließen, allerdings mit der Einschränkung, dass sich Teams über Zeit verändern. Die Kunst liegt in der Balance zwischen ausreichend Daten für statistische Stabilität und aktuellen Daten, die die gegenwärtige Leistungsfähigkeit widerspiegeln.
Die Gefahr voreiliger Schlussfolgerungen ist im Fußball besonders groß, weil Fans und Medien Erklärungen für jedes Ergebnis suchen. Wenn ein Team dreimal in Folge verliert, werden Gründe gesucht: Der Trainer ist schuld, die Taktik funktioniert nicht, die Spieler sind nicht in Form. Manchmal stimmt das, manchmal ist es einfach Zufall. Die Statistik hilft, diese Fälle zu unterscheiden, aber nur bei ausreichender Datenbasis.
Ein verwandtes Problem ist das Data Mining, also das Durchsuchen von Daten nach Mustern, bis man etwas findet. Wenn man genug Variablen testet, findet man immer eine Korrelation, auch wenn sie zufällig ist. Seriöse statistische Analysen definieren ihre Hypothesen vor der Datenanalyse und korrigieren für multiple Tests.
Von der Statistik zur Wette
Für viele Nutzer von KI-Prognosen ist die praktische Frage, wie man statistische Erkenntnisse in Wettentscheidungen übersetzen kann. Der Schlüssel liegt im Vergleich zwischen den berechneten Wahrscheinlichkeiten und den Wettquoten.
Die Umrechnung von Wahrscheinlichkeiten in Quoten ist einfach: Die faire Quote entspricht eins geteilt durch die Wahrscheinlichkeit. Bei einer Siegwahrscheinlichkeit von 50 Prozent ist die faire Quote 2,0. Bei 25 Prozent ist sie 4,0. Bei 80 Prozent ist sie 1,25. Diese fairen Quoten sind die Werte, die ein Wettanbieter anbieten würde, wenn er keinen Gewinn machen wollte.
In der Realität liegt die angebotene Quote immer unter der fairen Quote, weil der Buchmacher seine Marge einrechnet. Die sogenannte implizite Wahrscheinlichkeit der Quoten liegt daher über 100 Prozent, wenn man alle möglichen Ausgänge zusammenzählt. Der Unterschied zur fairen Quote ist der Buchmachervorteil, oft als Overround oder Vigorish bezeichnet.
Der zentrale Begriff beim statistischen Wetten ist Value. Eine Wette hat Value, wenn die eigene berechnete Wahrscheinlichkeit höher ist als die implizite Wahrscheinlichkeit der Quote. Wenn ein KI-Modell Bayern eine Siegwahrscheinlichkeit von 65 Prozent gibt und die Quote 1,60 beträgt, was einer impliziten Wahrscheinlichkeit von 62,5 Prozent entspricht, dann liegt Value vor. Die Wette hat einen positiven Erwartungswert.
Der Erwartungswert einer Wette berechnet sich als: Wahrscheinlichkeit mal Gewinn minus Gegenwahrscheinlichkeit mal Einsatz. Bei einem Einsatz von 10 Euro auf Quote 1,60 und einer angenommenen Wahrscheinlichkeit von 65 Prozent ergibt sich: 0,65 mal 6 Euro Gewinn minus 0,35 mal 10 Euro Einsatz, also 3,90 minus 3,50, gleich 0,40 Euro. Langfristig würde diese Wette also 0,40 Euro pro 10 Euro Einsatz einbringen.
Die praktische Herausforderung ist natürlich, die Wahrscheinlichkeiten richtig einzuschätzen. Das ist der Punkt, an dem die KI-Modelle ins Spiel kommen. Sie nutzen die statistischen Methoden, die wir besprochen haben, um Wahrscheinlichkeiten zu berechnen, die hoffentlich genauer sind als die des Marktes. Aber auch die besten Modelle haben eine Fehlerquote, und langfristiger Erfolg erfordert Disziplin und Geduld.
Bayesianische Methoden im Fußball
Neben den klassischen frequentistischen Ansätzen gewinnen bayesianische Methoden in der Fußballanalyse zunehmend an Bedeutung. Der Unterschied liegt in der Interpretation von Wahrscheinlichkeiten und im Umgang mit Unsicherheit.
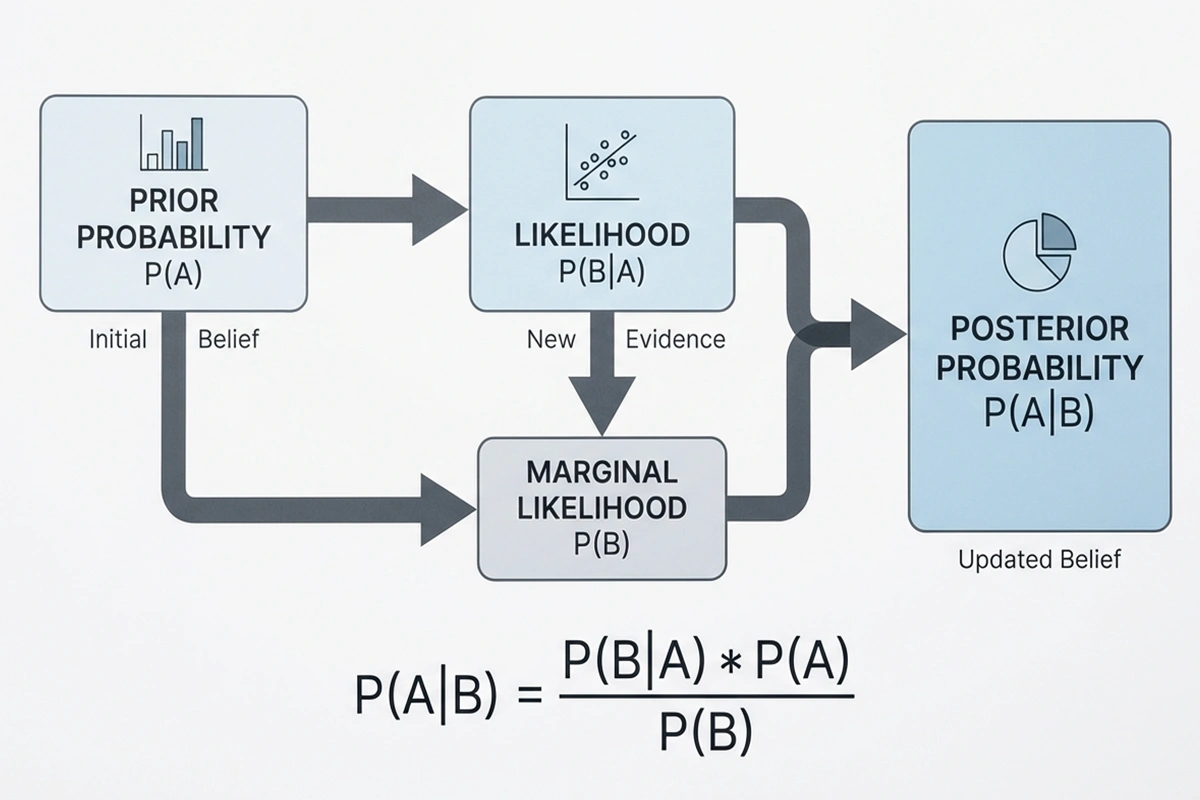
Der bayesianische Ansatz beginnt mit einer Vorannahme, dem sogenannten Prior. Diese Vorannahme kann auf historischen Daten, Expertenwissen oder allgemeinen Überlegungen basieren. Wenn ein Team neu in der Champions League ist und keine CL-Historie hat, könnte der Prior auf seiner Ligaleistung basieren. Bei einem etablierten Teilnehmer fließt die CL-Erfahrung ein.
Der entscheidende Schritt ist die Aktualisierung des Priors durch neue Daten. Jedes Spiel liefert Informationen, die die Einschätzung verändern. Ein Team, das überraschend stark auftritt, wird hochgestuft, eines, das enttäuscht, abgewertet. Die mathematische Grundlage ist das Bayes-Theorem, das beschreibt, wie Vorannahmen und Daten zu einer neuen Einschätzung kombiniert werden.
Für die Praxis bedeutet das: Bayesianische Modelle sind flexibler im Umgang mit unvollständigen Daten. Wenn über ein Team wenig bekannt ist, bleibt die Unsicherheit in der Schätzung hoch. Mit mehr Daten wird die Schätzung präziser. Klassische Modelle haben oft Probleme mit kleinen Stichproben, bayesianische Modelle können damit eleganter umgehen.
Die Implementierung bayesianischer Modelle ist allerdings technisch anspruchsvoller. Die Berechnungen erfordern oft spezielle Algorithmen wie Markov-Chain-Monte-Carlo-Methoden, die rechenintensiv sind. Deshalb setzen nicht alle Vorhersagesysteme bayesianische Ansätze ein, auch wenn sie theoretische Vorteile bieten.
Ein praktisches Beispiel: Ein Team hat in der Liga einen xG-Durchschnitt von 1,8 und in den ersten drei CL-Spielen einen Durchschnitt von 2,4. Ein frequentistisches Modell würde vielleicht den CL-Wert nehmen oder einen einfachen Durchschnitt bilden. Ein bayesianisches Modell würde den Liga-Prior mit den CL-Daten kombinieren und dabei berücksichtigen, dass drei Spiele wenig Aussagekraft haben. Das Ergebnis wäre ein Wert zwischen 1,8 und 2,4, näher an 1,8, weil die Datenbasis dort größer ist.
Die Grenzen statistischer Methoden
Bei aller Eleganz der Statistik ist es wichtig, ihre Grenzen zu kennen. Statistische Modelle sind Vereinfachungen der Realität, und manche Aspekte des Fußballs lassen sich nur schwer in Zahlen fassen.
Das offensichtlichste Problem ist die Unvorhersehbarkeit einzelner Ereignisse. Statistik macht Aussagen über Wahrscheinlichkeiten, nicht über konkrete Ergebnisse. Ein Modell kann sagen, dass Bayern zu 70 Prozent gewinnt, aber es kann nicht sagen, ob dieses konkrete Spiel zu den 70 oder zu den 30 Prozent gehört. Diese fundamentale Unsicherheit lässt sich nicht wegrechnen.
Psychologische Faktoren sind ein weiteres Gebiet, das statistisch schwer zu erfassen ist. Die Nervosität eines Spielers, die Motivation einer Mannschaft, die Stimmung im Stadion beeinflussen das Spiel, aber sie sind nicht in den Daten enthalten, mit denen die Modelle arbeiten. Manche Modelle versuchen, diese Faktoren durch Proxy-Variablen zu approximieren, aber das ist immer unvollständig.
Die Qualität der Daten setzt Grenzen. Statistische Modelle sind nur so gut wie die Daten, mit denen sie gefüttert werden. Fehlerhafte oder unvollständige Daten führen zu fehlerhaften Vorhersagen. Und selbst bei perfekten Daten bleibt das Problem, dass vergangene Leistung die Zukunft nicht garantiert.
Schließlich gibt es das philosophische Problem der Anwendbarkeit von Wahrscheinlichkeiten auf einmalige Ereignisse. Ein Champions-League-Finale findet genau einmal statt. Was bedeutet es zu sagen, dass Team A eine Siegwahrscheinlichkeit von 55 Prozent hat? Es gibt keine Wiederholungen, anhand derer man diese Wahrscheinlichkeit verifizieren könnte. Die Statistik macht trotzdem Aussagen, aber ihre Interpretation erfordert ein Verständnis für die Grenzen des Konzepts.
Der Wert statistischer Bildung
Die Beschäftigung mit den statistischen Grundlagen von KI-Vorhersagen mag abstrakt erscheinen, aber sie hat einen konkreten Nutzen. Wer die Methoden versteht, kann die Ergebnisse besser einordnen, realistische Erwartungen entwickeln und klügere Entscheidungen treffen.
Das wichtigste Takeaway ist vielleicht, dass Wahrscheinlichkeiten keine Garantien sind. Eine 70-Prozent-Siegwahrscheinlichkeit bedeutet, dass in drei von zehn Fällen das Gegenteil eintritt. Das ist nicht selten, sondern normal. Wer das internalisiert, reagiert gelassener auf einzelne Fehlprognosen und behält den langfristigen Blick.
Die zweite Erkenntnis betrifft die Bedeutung von Stichprobengrößen. Kurzfristige Ergebnisse sagen wenig aus, und erst über viele Spiele zeigt sich, ob ein Modell oder eine Strategie funktioniert. Geduld ist nicht nur eine Tugend, sondern eine statistische Notwendigkeit.
Drittens schärft das Verständnis der Methoden den kritischen Blick auf Anbieter. Wer die Grundlagen kennt, kann besser beurteilen, ob eine Plattform seriös arbeitet oder ob sie mit Scheinpräzision operiert. Die Frage, ob ein Modell grundsätzlich sinnvoll konstruiert ist, lässt sich nur beantworten, wenn man die Prinzipien versteht.
Praktische Beispiele statistischer Analyse
Um die abstrakte Theorie greifbarer zu machen, lohnt sich ein Blick auf konkrete Anwendungsfälle. Die folgenden Beispiele illustrieren, wie statistische Methoden in der Praxis eingesetzt werden.

Nehmen wir an, ein KI-System prognostiziert für das Spiel Bayern München gegen FC Barcelona folgende Wahrscheinlichkeiten: 45 Prozent Heimsieg, 28 Prozent Unentschieden, 27 Prozent Auswärtssieg. Diese Zahlen basieren auf einer Poisson-Simulation mit Erwartungswerten von 1,7 Toren für Bayern und 1,4 für Barcelona.
Wie kommen diese Erwartungswerte zustande? Eine Regressionsanalyse hat die relevanten Faktoren identifiziert: den xG-Durchschnitt der letzten zehn Spiele, adjustiert für Gegnerstärke, den Heimvorteil, der in der Champions League etwa 0,2 Tore ausmacht, und die historische CL-Performance beider Teams. Die Gewichte der einzelnen Faktoren wurden anhand vergangener Daten optimiert.
Die Elo-Ratings liefern eine zusätzliche Perspektive. Bayern hat vielleicht ein Rating von 2050, Barcelona von 2020. Der Unterschied von 30 Punkten entspricht einer leichten Favoritenrolle für Bayern, etwa 53 Prozent Siegwahrscheinlichkeit in einem Einzelspiel. Das stimmt nicht exakt mit der Poisson-Prognose überein, was normal ist, denn verschiedene Modelle liefern leicht unterschiedliche Ergebnisse.
Ein Analyst würde nun beide Ansätze kombinieren und vielleicht weitere Faktoren einbeziehen: Ist ein Schlüsselspieler verletzt? Wie wichtig ist das Spiel für beide Teams? Hat eines der Teams zuletzt auffällig über- oder unterperformt? Die statistische Basis liefert den Ausgangspunkt, die qualitative Analyse kann Korrekturen vornehmen.
Der Vergleich mit den Wettquoten zeigt, ob Value vorhanden ist. Wenn die Quote für einen Bayern-Sieg bei 2,10 liegt, entspricht das einer impliziten Wahrscheinlichkeit von etwa 48 Prozent. Die Prognose von 45 Prozent liegt darunter, was bedeutet, dass die Wette keinen positiven Erwartungswert hat. Bei einer Quote von 2,30, also 43 Prozent implizit, sähe es anders aus.
Die Statistik ist kein Zauberstab, der alle Unsicherheiten beseitigt. Sie ist ein Werkzeug, das hilft, mit Unsicherheit umzugehen. Und in einem Spiel wie Fußball, wo Überraschungen zum Wesen gehören, ist das ein wertvoller Beitrag.